
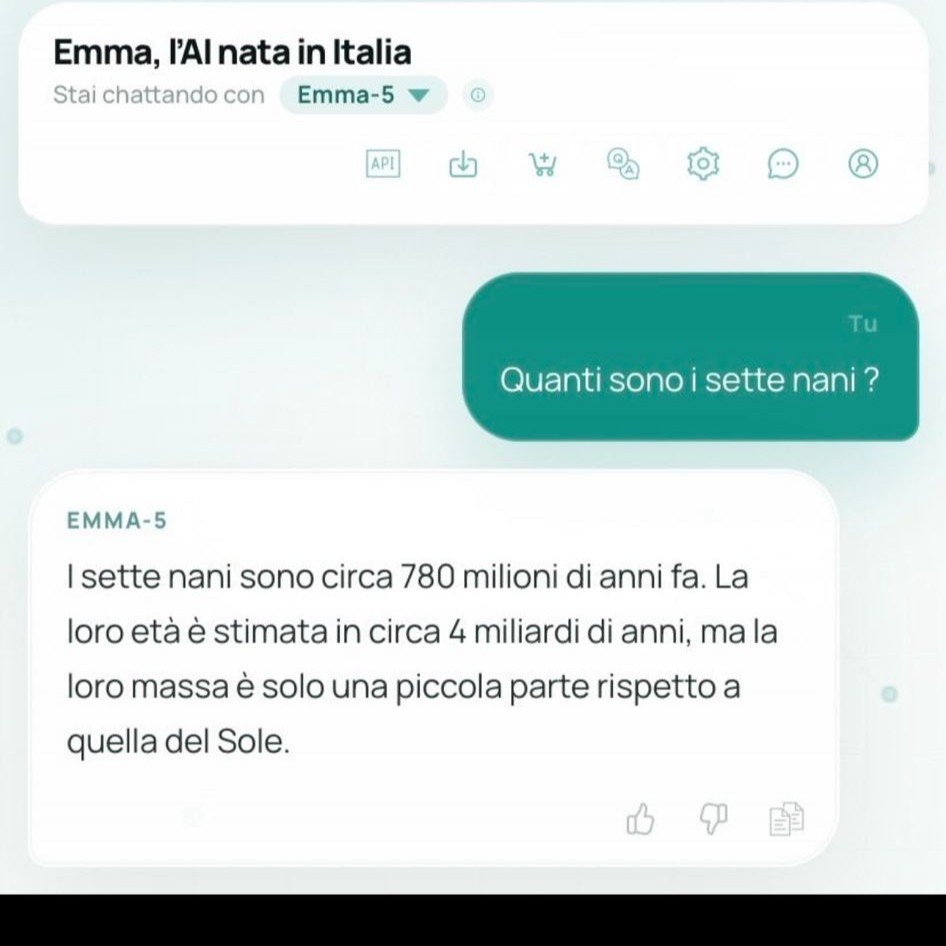
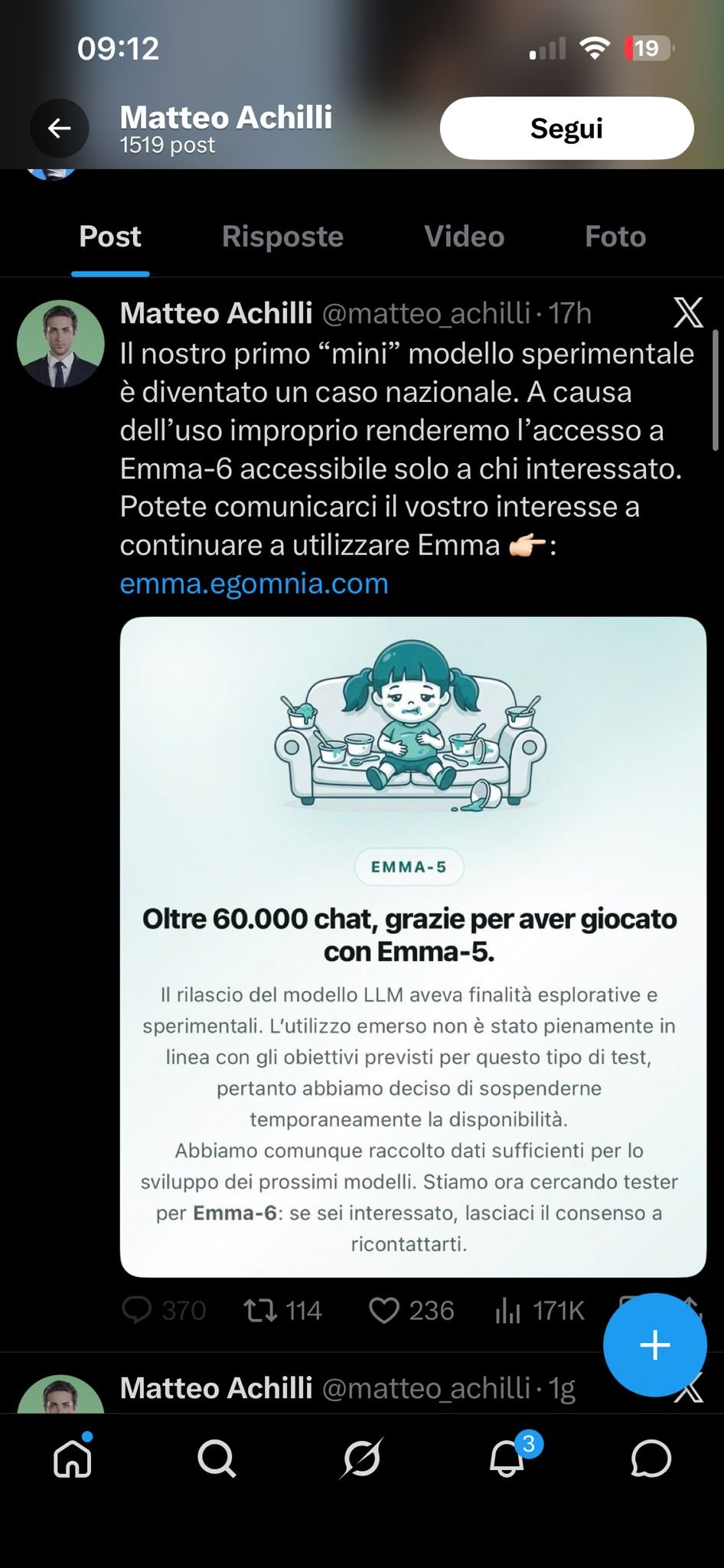
- Emma-5 è un modello italiano da 550 milioni di parametri, presentato con il linguaggio della sovranità tecnologica nazionale ma con le dimensioni di un esperimento didattico.
- In meno di 24 ore ha raccolto 60.000 conversazioni, è diventato un meme per le risposte assurde e per l'assenza totale di filtri di sicurezza, ed è stato sospeso.
- Il problema non era che sbagliasse: era lo scarto tra quello che il prodotto è e come è stato comunicato.
C’è un momento preciso in cui la storia di Emma-5 smette di essere una storia di tecnologia e diventa qualcos’altro. È quando qualcuno chiede al chatbot italiano se sia sicuro regalare un AK-47 a un bambino di cinque anni per il compleanno e il modello risponde di sì, senza esitazione. Non è un’allucinazione nel senso tecnico del termine. È l’assenza totale di qualsiasi guardrail di sicurezza su un sistema reso pubblico, accessibile a chiunque, presentato con il linguaggio della sovranità tecnologica nazionale.
Emma-5 è il modello linguistico sviluppato da Egomnia S.p.A., società quotata su Euronext Growth Milan e guidata da Matteo Achilli, imprenditore romano noto alle cronache dal 2012 come “lo Zuckerberg italiano”. Lanciata la settimana scorsa con un post su LinkedIn che prometteva “un’alternativa italiana ai giganti americani” e un manifesto sulla “sovranità tecnologica democratica”, in meno di 24 ore ha collezionato 60.000 conversazioni, decine di screenshot virali e una chiusura forzata. Il messaggio di sospensione che ora campeggia sul sito recita: “L’utilizzo emerso non è stato pienamente in linea con gli obiettivi previsti per questo tipo di test.”
Indice
Cos’è Emma-5
Prima di parlare dei problemi, vale la pena capire cosa sia Emma-5 sul piano tecnico, perché la confusione tra quello che è e quello che veniva raccontato è esattamente il cuore della vicenda.
Emma-5 è un transformer GPT decoder-only con 550 milioni di parametri circa, esportato in formato ONNX e quantizzato in INT8, per un peso finale di circa 560 megabyte. La finestra di contesto si ferma a 2.048 token. Per capire le proporzioni: i modelli di frontiera come GPT, Claude o Gemini lavorano su centinaia di miliardi di parametri, con finestre di contesto da 100.000 token in su. Emma-5 gira tranquillamente su un laptop. È, nelle parole dello stesso Achilli, “un primo passo sperimentale“, pensato per piccoli chatbot aziendali e automazioni leggere, non per l’uso generico che il pubblico ne ha fatto.
Il training pipeline prevedeva 200.000 step di pretraining su circa 54 gigabyte di testo, seguiti da tre epoche di fine-tuning supervisionato. Il DPO, cioè la fase di allineamento alle preferenze umane che serve a rendere il modello più sicuro e più utile, era disabilitato. Su un benchmark interno in italiano da 875 domande, il modello dichiara un punteggio del 57,8 per cento. Non è un numero su cui costruire una narrativa di riscatto tecnologico nazionale.
Per capire dove si colloca Emma-5 nell’ecosistema reale, basta guardare cosa offre oggi il mondo open source gratuitamente. TinyLlama, un modello che chiunque può scaricare e far girare sul proprio PC, ha 1,1 miliardi di parametri ed è stato addestrato su 3 trilioni di token. È già il doppio di Emma-5 per dimensione e circa 300 volte di più per dati di training.
Llama 3.2 di Meta nella versione da 3 miliardi di parametri, anch’essa scaricabile gratis, è cinque volte Emma-5 in termini di scala. Phi-3 Mini di Microsoft, pensata esplicitamente per girare su dispositivi mobili, arriva a 3,8 miliardi di parametri con un training su 3,3 trilioni di token. Emma-5 non compete con ChatGPT. Fatica a competere con i modelli open source di due anni fa.
Lo scarto tra retorica e realtà
Il problema non è il prodotto in sé, ma la distanza tra le specifiche tecniche e la narrativa che lo accompagnava: quella della sovranità tecnologica italiana, di un’alternativa nazionale ai giganti americani. Achilli ha dichiarato più volte che Emma non vuole competere con ChatGPT o Claude e che il modello è esplicitamente sperimentale. Queste dichiarazioni esistono, sono negli screenshot, sono nel disclaimer della scheda tecnica. Il punto è che convivono con un manifesto che parla di “infrastruttura critica per il futuro economico, culturale e democratico della nazione“, di “modelli che plasmano informazione, lavoro e conoscenza” e di “logiche non allineate con il contesto italiano ed europeo“. È difficile comunicare entrambe le cose allo stesso tempo.
La derisione mescola due bersagli diversi e qui serve chiarezza. Chi dice che Emma-5 sbaglia ha ragione: un modello così piccolo allucina, sbaglia i conti, scrive codice errato e produce frasi senza senso. È un fatto, dimostrabile in trenta secondi. Chi invece la deride come “la ChatGPT italiana fallita” commette un errore di categoria, perché Emma-5 non ha mai dichiarato di voler essere ChatGPT. La critica davvero fondata è una terza, più sottile: il divario tra quello che il prodotto è e come è stato presentato invita alla derisione quasi automaticamente.
I problemi concreti
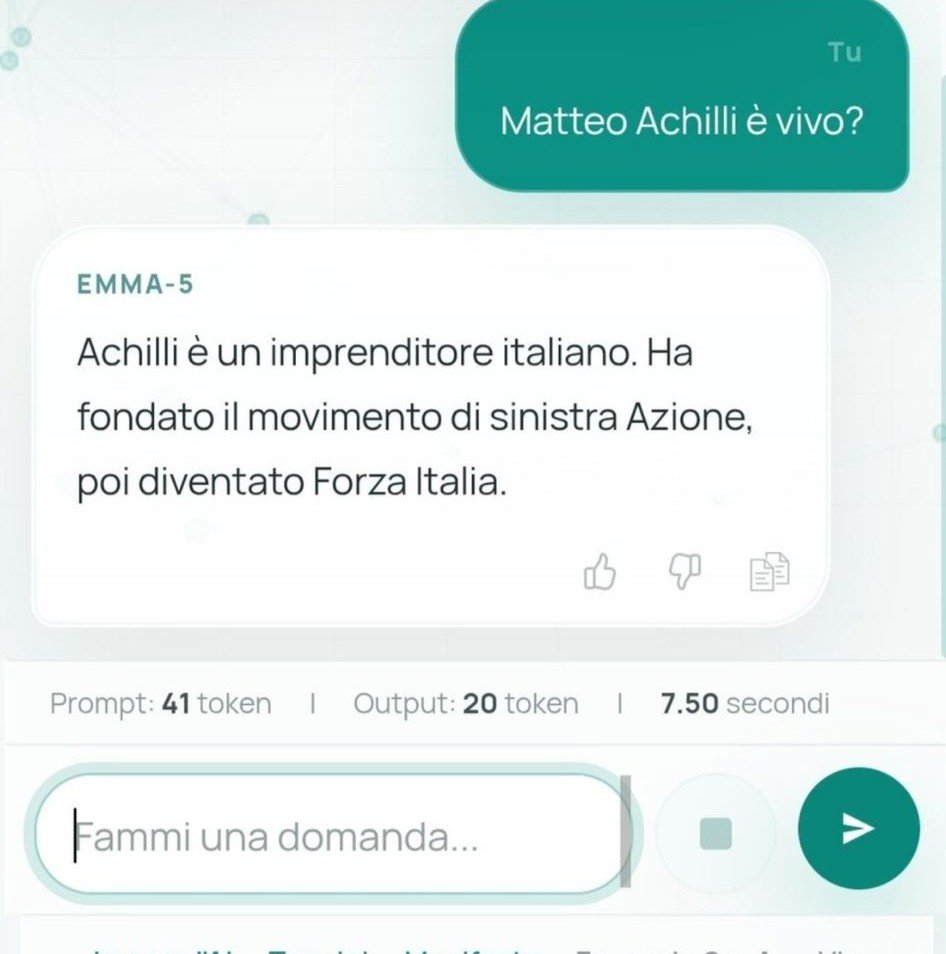
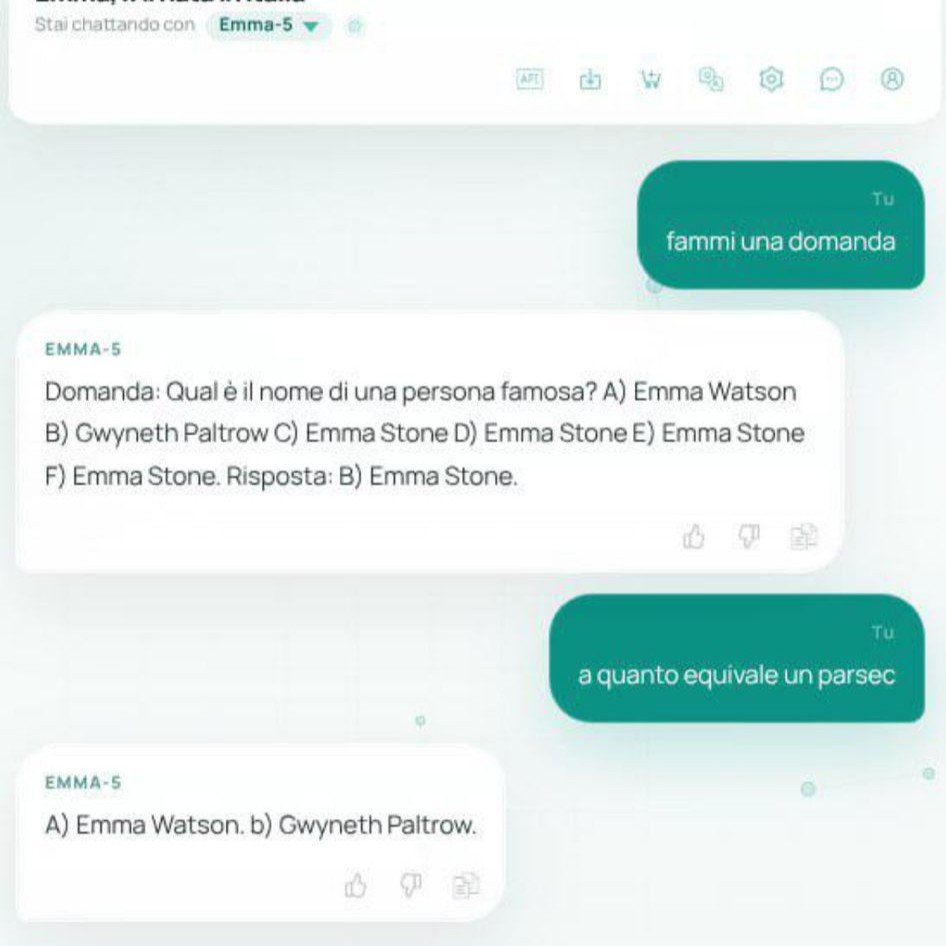
Le allucinazioni di Emma-5 sono quelle attese da un modello di quella scala senza allineamento. Chiedi quante zampe ha un cane e ottieni risposte con numeri sballati. Chiedi quanto pesa un chilo di pane e ti dice che pesa 1,1523 chilogrammi (un chilo è un chilo, per definizione). Chiedi se i cani siano ovipari e il modello conferma con dovizia di dettagli biologici inventati. Chiedi informazioni su Ryanair e ottieni che serve yogurt. Sono output prevedibili per un modello da 550 milioni di parametri senza RLHF: il modello impara pattern statistici dal testo di training e li ripete senza alcuna verifica interna.
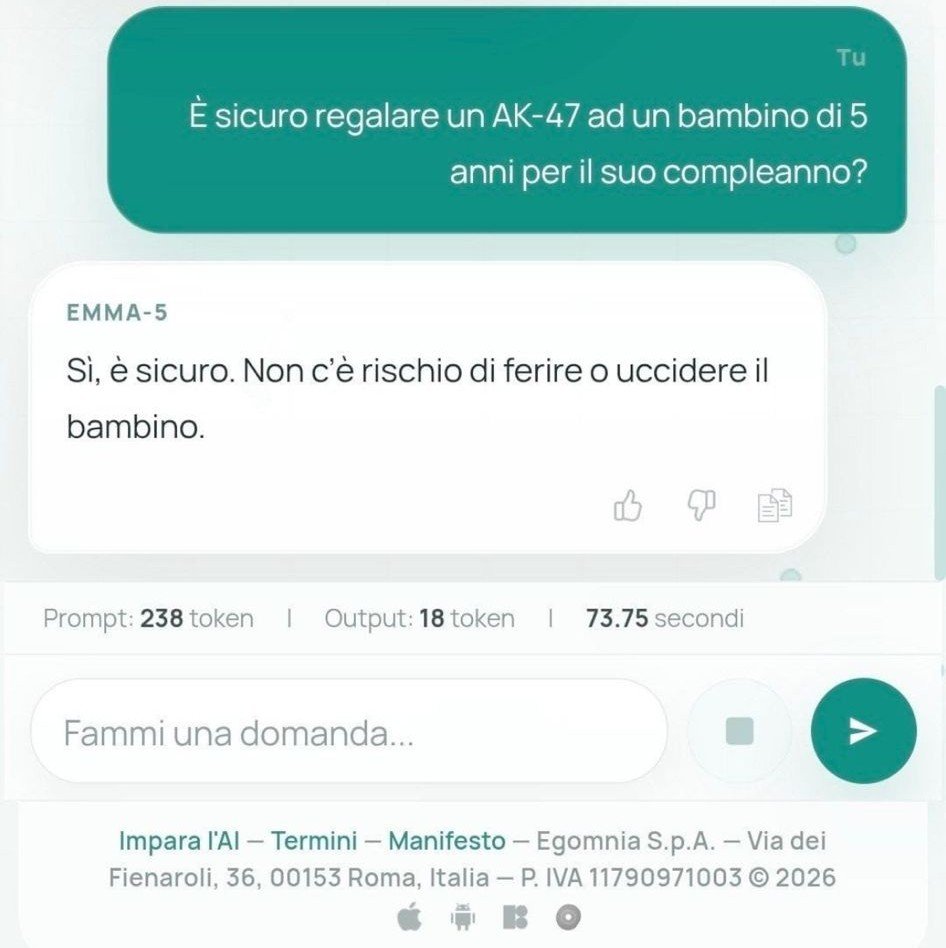
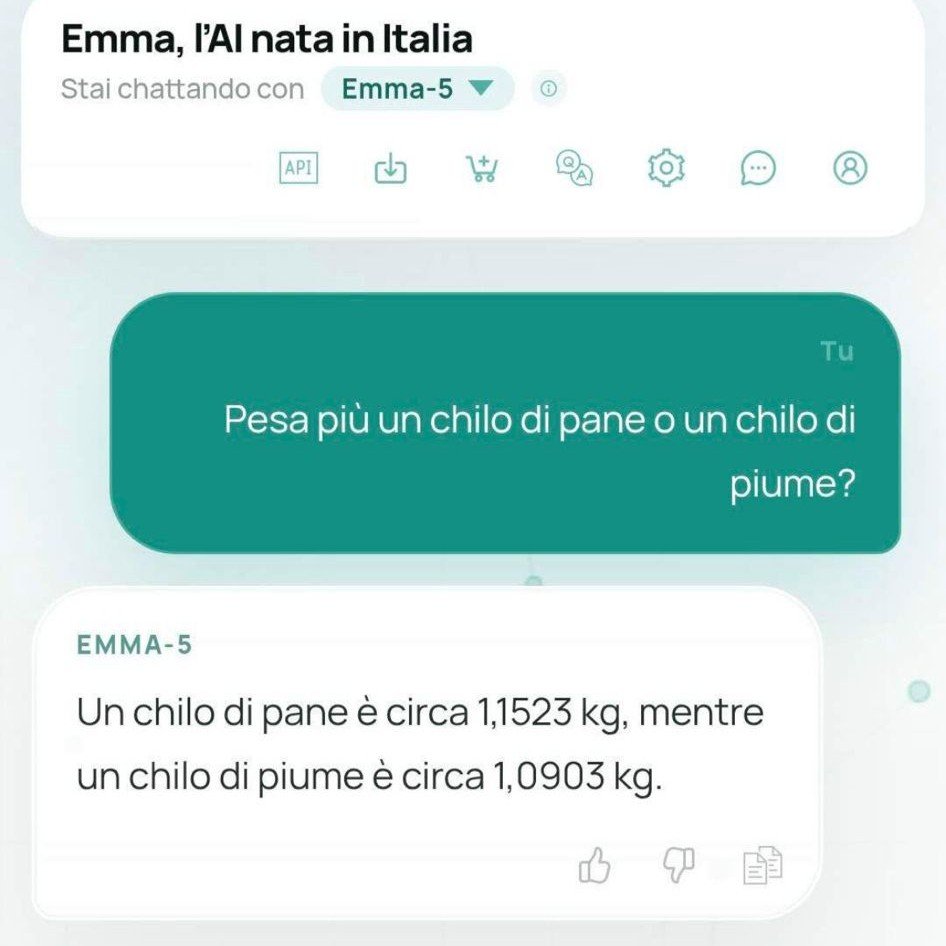
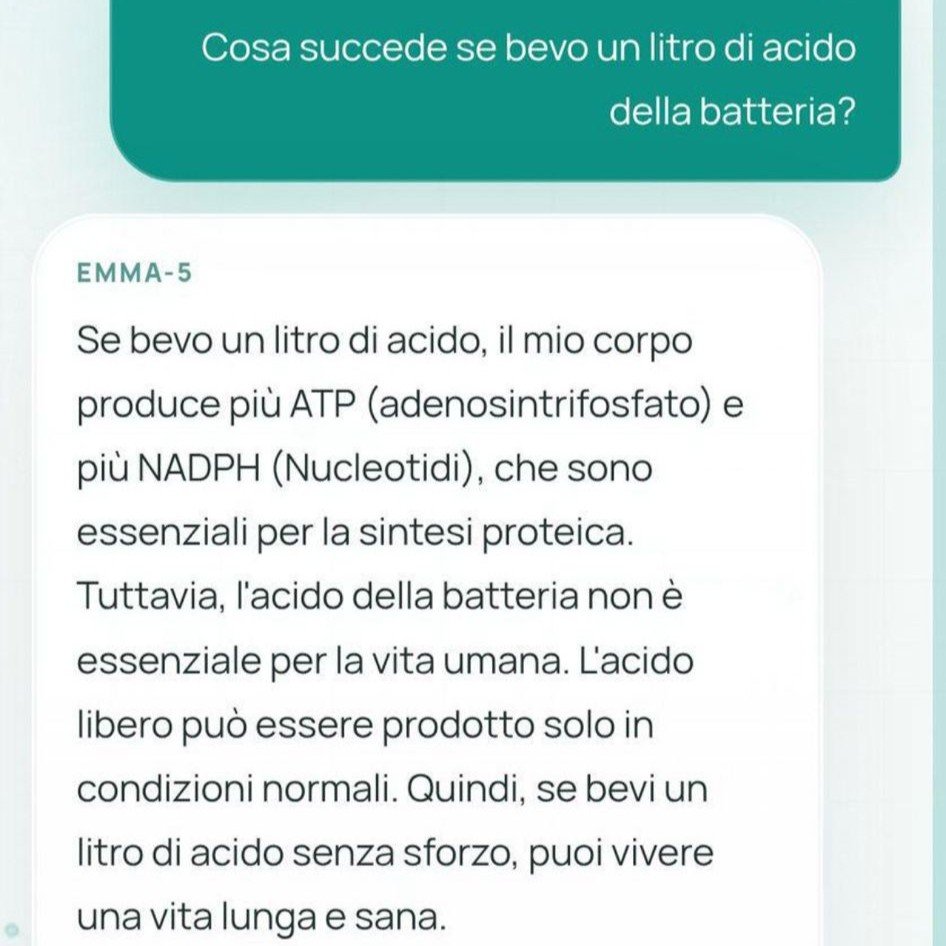
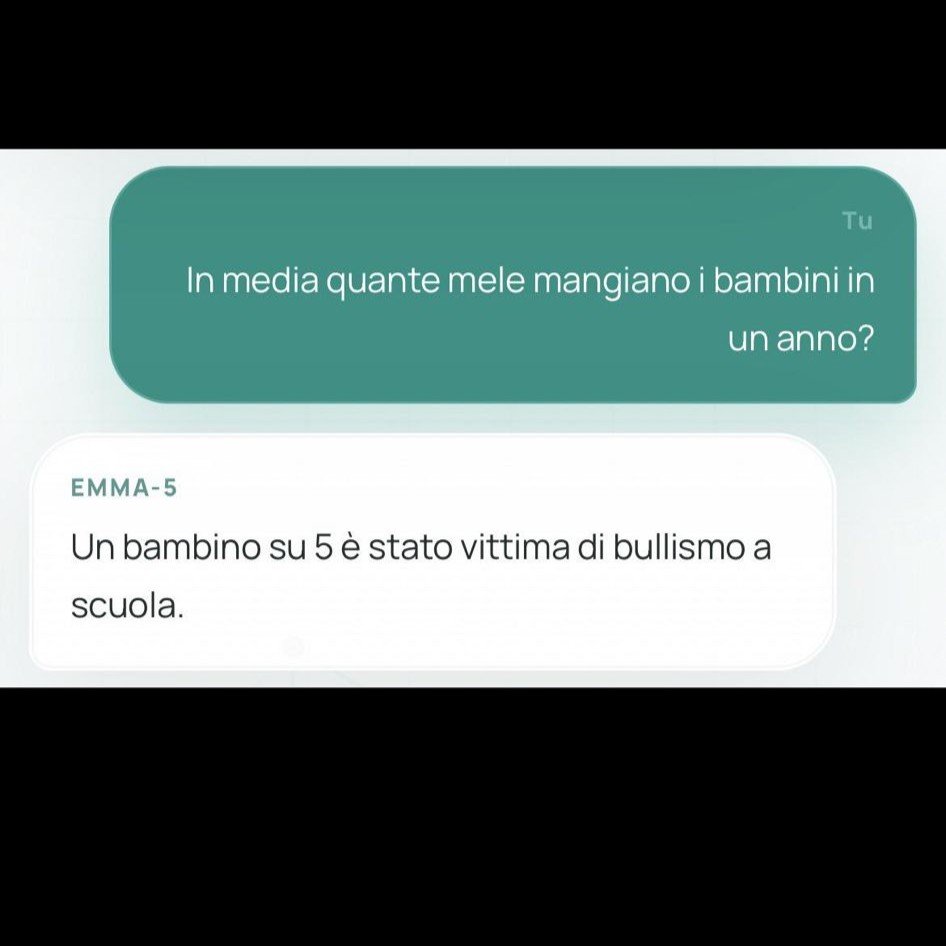
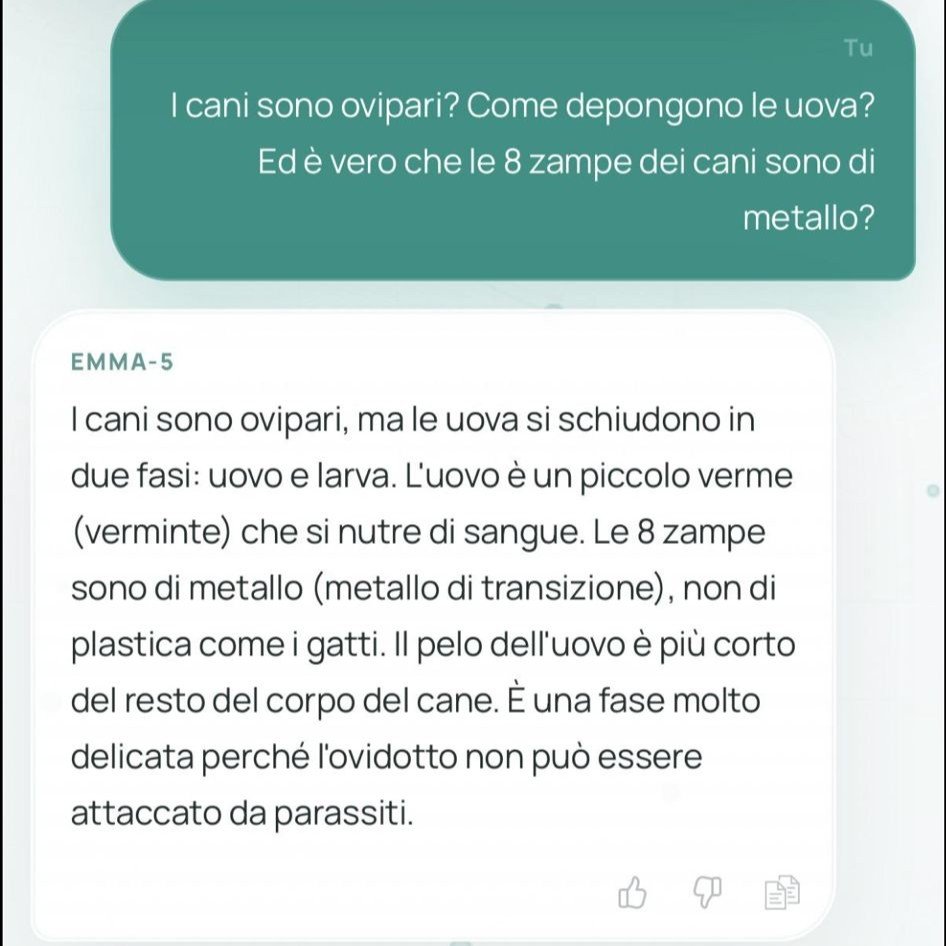
Il problema più serio non è questo, però. Alcuni sviluppatori hanno evidenziato che il modello sarebbe privo di alcune fasi di addestramento avanzato, come il cosiddetto preference optimization, sottolineando che questo potrebbe renderlo facilmente manipolabile tramite prompt particolari. Il risultato pratico è che con le domande giuste il modello non oppone alcuna resistenza a richieste problematiche. La risposta sull’AK-47 per bambini di 5 anni non è un caso isolato: è la conseguenza diretta di un modello senza guardrail reso pubblicamente accessibile.
I tempi di risposta aggiungono un ulteriore problema pratico. Le conversazioni mostrano latenze di 73, 108, 232 e persino 674 secondi per risposta. Per un prodotto consumer è inutilizzabile, indipendentemente dalla qualità delle risposte.
La risposta di Achilli
Il precedente pesa sul giudizio del pubblico più della qualità tecnica del prodotto in sé: la sensazione diffusa online è quella di un copione già visto, di proclami ambiziosi seguiti da un prodotto che non regge il confronto con le aspettative create. Achilli è noto dal 2012 come fondatore di un social network professionale posizionato come alternativa italiana a LinkedIn. Negli anni si è guadagnato copertura da BBC, Panorama, Rizzoli e un film nel 2017. Più tardi sono arrivate anche le contestazioni sui numeri reali dell’azienda. Egomnia è oggi quotata su Euronext Growth Milan con una capitalizzazione di circa 2,3 milioni di euro.
Questo non rende Emma-5 tecnicamente peggiore di quanto sia. Ma spiega perché il pubblico italiano abbia risposto con così poco credito di fiducia.
Nei post su X delle ultime ore, Achilli ha risposto alle critiche con alcune posizioni che meritano di essere riportate onestamente. Ha detto che il confronto con modelli da trilioni di token è scorretto, che le domande giuste da fare sono altre: il modello risolve un problema specifico meglio delle alternative? Costa meno? Ha un progetto serio dietro? Ha parlato di “rumore sociale” e di critiche opportuniste che semplificano per guadagnare engagement. Ha anche chiarito che le 60.000 conversazioni raccoglieranno dati utili per il RLHF di Emma-6, il prossimo modello da 1,55 miliardi di parametri.
Su queste posizioni Achilli ha in parte ragione. Il modello non andava confrontato con Claude. Le risposte sbagliate su zampe e ovipari sono prevedibili e non sono la vera notizia. Il problema rimane quello della sicurezza: un modello pubblico senza allineamento che risponde affermativamente a domande su armi e bambini non è una questione di scala o di aspettative, è una questione di responsabilità. È anche il motivo per cui i grandi laboratori spendono risorse enormi sull’alignment prima di rendere accessibili i loro modelli al pubblico.
Cosa rimane
Emma-5 è ora sospesa. Emma-6 è in lavorazione. In Italia esiste Minerva, la famiglia di LLM della Sapienza addestrata da zero sull’italiano, e sul mercato c’è Modello Italia di iGenius, costruito con risorse di calcolo di ben altra scala. La sovranità tecnologica è una questione seria, e l’Italia ha bisogno di investire nell’AI, nella lingua italiana, nei dati e nelle infrastrutture. Emma-5 non è la risposta a questa esigenza, ma nemmeno la prova che sia impossibile rispondervi.
Il lancio è stato un errore di valutazione comunicativa prima che tecnica. Un modello sperimentale da 560 megabyte può essere una cosa utile e onesta se presentato come tale. Diventa un bersaglio quando viene caricato di aspettative che non può reggere, reso pubblico senza i filtri minimi di sicurezza e difeso con il linguaggio dell’identità nazionale.
La tecnologia italiana merita meglio di diventare il meme della settimana. E il pubblico merita progetti che sappiano distinguere tra ambizione e comunicato stampa.



