
MiniMax ha rilasciato MiniMax-M1, il primo grande modello di ragionamento a pesi aperti basato su un'architettura Mixture-of-Experts (MoE) e meccanismo lightning attention. Sviluppato a partire da MiniMax-Text-01, il modello conta 456 miliardi di parametri totali (45,9 miliardi attivati per token), supporta una finestra di contesto nativa di 1 milione di token ed abbatte del 75% i requisiti computazionali nei testi lunghi rispetto a DeepSeek R1. I modelli sono disponibili in due varianti focalizzate su budget di pensiero differenti.
Il panorama dei grandi modelli linguistici dedicati al calcolo logico accoglie una pietra miliare tecnologica destinata a scuotere i vertici del settore. MiniMax ha annunciato il rilascio ufficiale di MiniMax-M1, il primo modello di ragionamento su larga scala al mondo a pesi aperti (open-weight) basato su un’innovativa architettura ad attenzione ibrida. Il cuore del sistema fonde la flessibilità di una struttura Mixture-of-Experts (MoE) con la velocità computazionale del meccanismo lightning attention.
Sviluppato prendendo come fondamenta il precedente modello di testo MiniMax-Text-01, il neonato M1 vanta una stazza monumentale composta da un totale di 456 miliardi di parametri complessivi, di cui 45,9 miliardi vengono attivati dinamicamente per ogni singolo token elaborato. La caratteristica ingegneristica più dirompente è il supporto nativo a una finestra di contesto pari a 1 milione di token, una capacità di immagazzinamento delle informazioni ben otto volte superiore rispetto a quella dichiarata dal celebre rivale DeepSeek R1.
Indice
Efficienza del calcolo in fase di inferenza e l’innovazione del framework CISPO
La combinazione tra i moduli MoE e la lightning attention è stata concepita per risolvere uno dei problemi più gravi e costosi dei modelli di ragionamento moderni, ovvero la scalabilità dei costi di calcolo durante la fase di generazione del testo. Nei compiti ad alta complessità che richiedono risposte estremamente articolate, MiniMax-M1 dimostra un’efficienza straordinaria, arrivando a consumare appena il 25% dei FLOP richiesti da DeepSeek R1 su una lunghezza di generazione pari a 100.000 token. Questa architettura ibrida rende il modello lo strumento ideale per elaborare input massicci ed eseguire catene di pensiero estensive in locale o in ambiente aziendale.
L’addestramento del modello è stato condotto sfruttando tecniche di apprendimento per rinforzo (Reinforcement Learning) su scala industriale, sottoponendo gli algoritmi a una vasta gamma di problemi logici, dai classici quesiti matematici competitivi fino ad ambienti di ingegneria del software simulati in sandbox. All’interno del framework di scalabilità del Reinforcement Learning, il team di sviluppo ha introdotto due innovazioni cruciali:
- L’algoritmo CISPO: Una nuova metodologia che clicca i pesi dell’importanza del campionamento anziché limitarsi ad aggiornare i singoli token, facendo registrare prestazioni superiori rispetto a tutte le varianti concorrenti.
- Ottimizzazione dell’attenzione ibrida: Una configurazione studiata appositamente per superare le barriere legate alla distribuzione del carico di calcolo durante le sessioni di addestramento su cluster di GPU massicci.
L’azienda ha rilasciato l’hardware logico in due differenti configurazioni, ottimizzate per assecondare diversi scenari di utilizzo: MiniMax-M1-40k e MiniMax-M1-80k, i cui nomi indicano direttamente il budget di passaggi logici dedicati alla riflessione prima di emettere la risposta definitiva.
Analisi dei benchmark di settore: il confronto con DeepSeek, Claude e OpenAI
I dati ricavati dai test standardizzati indipendenti mostrano che la configurazione di punta MiniMax-M1-80k è in grado di surclassare modelli open-weight di altissimo profilo come Qwen3-235B e lo stesso DeepSeek R1 originale, evidenziando picchi di eccellenza proprio nei compiti legati all’utilizzo di strumenti, alla programmazione complessa e alla comprensione di contesti lunghi.
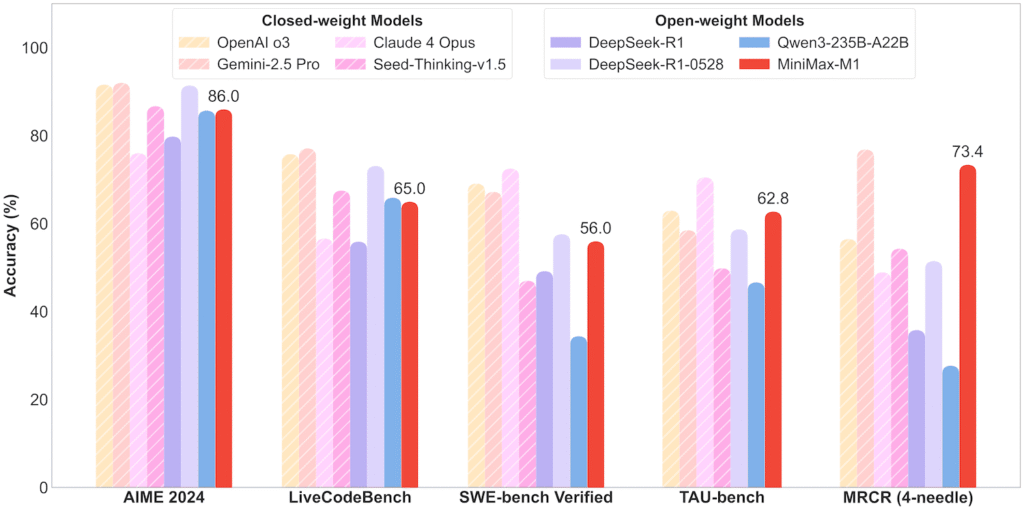
Tabella comparativa delle prestazioni sui principali benchmark di ragionamento
| Categoria e Benchmark | MiniMax-M1-80K | MiniMax-M1-40K | Qwen3-235B | DeepSeek-R1 (0528) | DeepSeek-R1 | OpenAI-o3 |
| Budget di Pensiero | 80K | 40K | 32k | 64k | 32k | 100k |
| AIME 2024 (Matematica) | 86.0 | 83.3 | 85.7 | 91.4 | 79.8 | 91.6 |
| AIME 2025 (Matematica) | 76.9 | 74.6 | 81.5 | 87.5 | 70.0 | 88.9 |
| MATH-500 (Logica) | 96.8 | 96.0 | 96.2 | 98.0 | 97.3 | 98.1 |
| LiveCodeBench (Coding) | 65.0 | 62.3 | 65.9 | 73.1 | 55.9 | 75.8 |
| SWE-bench Verified (Software) | 56.0 | 55.6 | 34.4 | 57.6 | 49.2 | 69.1 |
| OpenAI-MRCR (128k) (Contesto) | 73.4 | 76.1 | 27.7 | 51.5 | 35.8 | 56.5 |
| OpenAI-MRCR (1M) (Contesto) | 56.2 | 58.6 | — | — | — | — |
| LongBench-v2 (Contesto Lungo) | 61.5 | 61.0 | 50.1 | 52.1 | 58.3 | 58.8 |
| TAU-bench Airline (Agenti/Tool) | 62.0 | 60.0 | 34.7 | 53.5 | — | 52.0 |
| TAU-bench Retail (Agenti/Tool) | 63.5 | 67.8 | 58.6 | 63.9 | — | 73.9 |
Nell’analisi dei compiti di ingegneria del software su SWE-bench Verified, condotti escludendo i meccanismi di recupero basati su embedding in favore di un processo di localizzazione dei file a due stadi, il modello a 80k raggiunge un punteggio del 56.0%, distanziando nettamente il rivale Qwen3-235B fermo al 34.4%. Il vero trionfo si registra tuttavia nei test a contesto profondo: nel benchmark OpenAI-MRCR configurato a 1 milione di token, MiniMax-M1-40k fa registrare uno score del 58.6%, un terreno in cui la quasi totalità dei modelli commerciali e open-weight concorrenti non è in grado di operare a causa dei limiti strutturali della memoria.
Linee guida per l’ottimizzazione dell’inferenza e prompt di sistema
Per estrarre il massimo potenziale dalle routine logiche di MiniMax-M1, la casa madre consiglia l’adozione di specifici parametri di configurazione in fase di inferenza. La temperatura deve essere impostata tassativamente sul valore di 1.0, combinata con un valore di Top_p pari a 0.95. Questa calibrazione è l’impostazione ottimale per stimolare la creatività e la diversificazione delle risposte, consentendo all’algoritmo di esplorare una gamma più ampia di percorsi linguistici senza compromettere la coerenza logica della catena di scomposizione del problema.
Anche la configurazione dei prompt di sistema richiede accorgimenti precisi a seconda dello scenario operativo in cui l’agente viene inserito:
- Scenari Matematici e Logici: È essenziale forzare il ragionamento esplicito includendo nel prompt la direttiva di ragionare passo dopo passo inserendo la risposta finale all’interno del tag dedicato
\boxed{}. - Sviluppo Web e Generazione Codice: Il modello esprime le sue massime capacità quando viene istruito a operare come un ingegnere del software avanzato. I tecnici suggeriscono di richiedere l’output del codice all’interno di un singolo blocco di testo monolitico, integrando HTML e JavaScript senza separazioni, vietando l’inclusione di testi descrittivi aggiuntivi e forzando l’algoritmo a eseguire una verifica automatica degli errori prima del rendering visivo.
Perché MiniMax-M1 rappresenta una vera e propria rivoluzione nel settore AI
L’arrivo di questo modello non è un semplice aggiornamento tecnico, ma rappresenta un autentico cambio di paradigma per il mondo open-source e per lo sviluppo di agenti autonomi. Fino a oggi, la capacità di processare una finestra di contesto da 1 milione di token – necessaria per leggere contemporaneamente interi libri, smisurati database aziendali o complesse repository di codice – era un’esclusiva assoluta di costosissimi modelli proprietari e chiusi. Rompendo questo monopolio de facto, MiniMax-M1 democratizza l’accesso a capacità di ragionamento ultra-lunghe, garantendo al contempo a ricercatori e aziende il controllo totale sulla privacy dei propri dati sensibili grazie al rilascio dei pesi aperti.
Inoltre, l’unione inedita tra la tecnologia lightning attention e la struttura MoE risolve il più grande ostacolo alla diffusione dell’intelligenza artificiale generativa: i costi infrastrutturali. Abbattere il consumo di FLOP del 75% nelle elaborazioni estese significa che non servono più irraggiungibili server farm cloud per eseguire modelli agentici di altissimo livello. Questa innovazione trasforma le grandi intelligenze artificiali da strumenti dipendenti dal cloud a motori di ragionamento scalabili, fluidi e integrabili on-premise, ponendo di fatto le basi infrastrutturali per un futuro imminente in cui software completamente autonomi lavoreranno fianco a fianco con i professionisti nelle reti aziendali locali.




